
A new paper titled, Interpretable deep learning model for load and temperature forecasting: Depending on encoding length, models may be cheating on wrong answers has been published in Energy and Buildings.
Paper link

Summary
Data-driven time-series forecasting models for model predictive control of building energy systems have an autoregressive structure that accepts historical data as input. One customary practice is to encode the past 24 h of data to extract daily periodicity information when forecasting 24 h ahead. However, deep learning models have different forecasting mechanisms than traditional time-series models that decompose periodicity. This study focuses on the impact of encoding length in deep learning models used for building energy demand forecasting.
To investigate this, we developed an interpretable deep learning model using an attention mechanism and gated recurrent units. We tested three different encoding lengths: 8 hours, 24 hours, and 168 hours for 24-h-ahead forecasting of zone temperatures and loads.
The findings revealed that the choice of encoding length significantly impacts the model's forecasting behavior and performance. The 24-hour and 168-hour models rely heavily on daily periodicity information, while the 8-hour model depends more on recent state information. This makes the latter more adaptable to sudden changes, providing better accuracy when boundary conditions deviate from typical daily patterns.
The study suggests treating encoding length as a crucial hyperparameter to be optimized based on target characteristics, environmental conditions, and model architecture. It also highlights that an attention weight map can explain a model's inference mechanism which can help improve its performance by adjusting factors like encoding length.
Featured figures
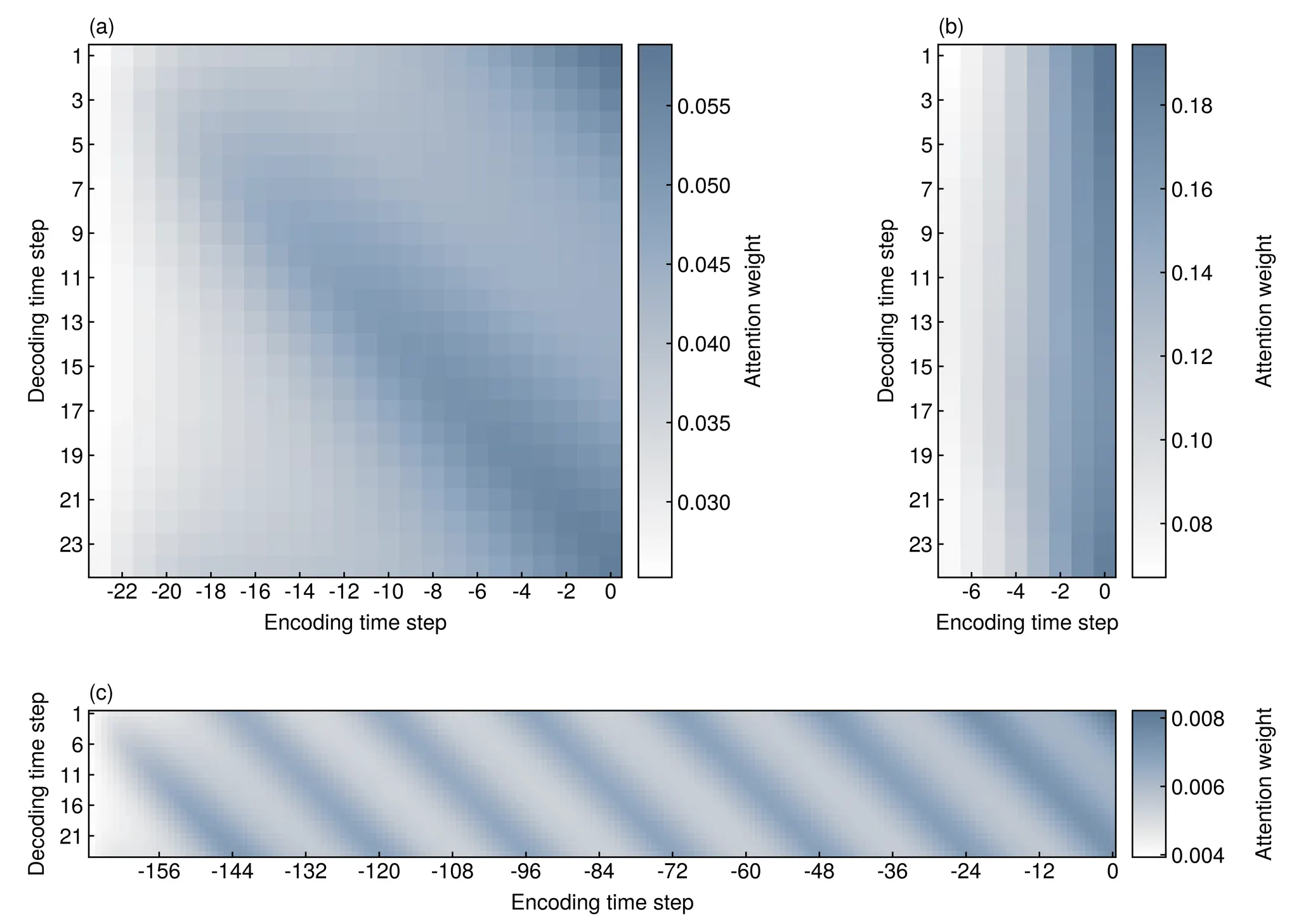
Attention maps of three different encoding length models; (a) 24-h model, (b) 8-h model, and (c) 168-h model
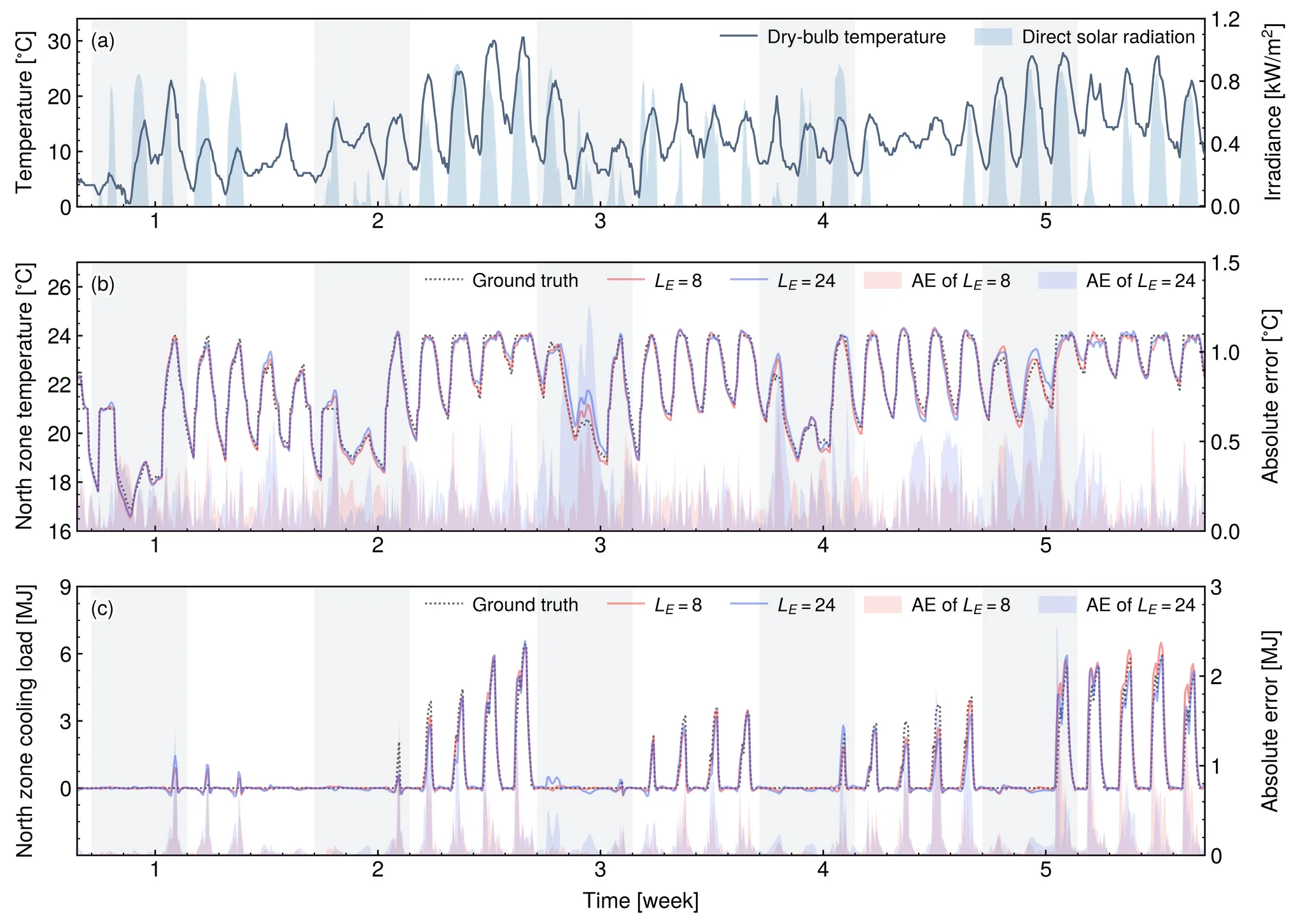
Performance comparison between 8-h and 24-h encoding length models